Partial AdGuard DNS outage on 29 November 2022
Yesterday, at 18:24 UTC AdGuard DNS experienced a serious outage that affected servers in 3 locations: Miami, New York, and London. During the outage the Internet was effectively broken for all customers connected to these 3 locations. This is about 20% of all AdGuard DNS customers, i.e. over 10 million people experienced issues with the Internet. We are truly sorry for this and we are taking steps to avoid having issues like that in the future.
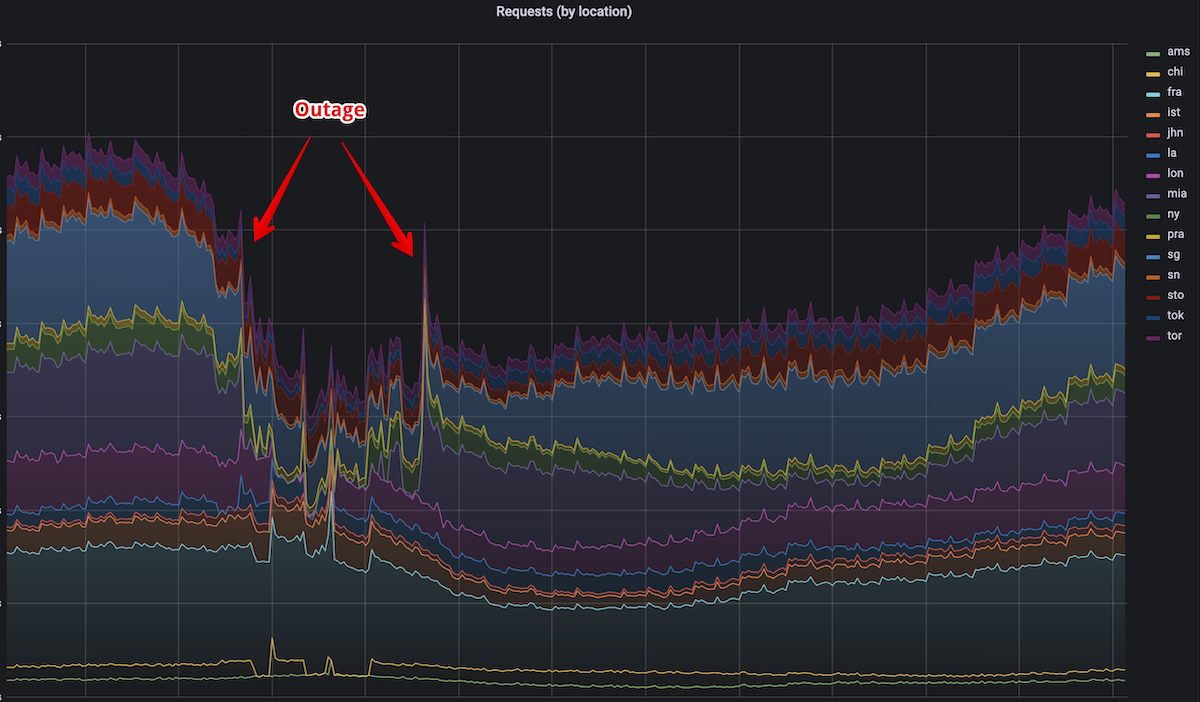
What happened
A number of small mistakes led to this issue. Each of these mistakes alone was not critical and would not lead to any disaster. Unfortunately, together they were just enough.
The first mistake was made two days ago when we renewed the TLS certificates for AdGuard DNS. The new certs were RSA and not ECDSA that we always use. The difference might not be obvious even for experienced developers, but it is very important for us. AdGuard DNS is written in Go and in addition to numerous advantages it also imposes some limitations. Initial TLS handshake with RSA is very slow in Go's crypto/tls and this issue is not going to be fixed any time soon. This performance issue mostly affects initial handshakes and not session resumptions so immediately after changing the certificates the CPU load increase was not too huge. But the bomb had been planted and waited for the best moment to detonate.
Note that plain unencrypted DNS is just about 10% of AdGuard DNS traffic. Most of the traffic is different encrypted protocols and performance-wise the heaviest part of any encryption is the handshake.
The wait was not too long. A day later we rolled out a change to the BGP configuration which was supposed to improve the traffic distribution for a couple of small ISPs. This new configuration shaked things pretty heavily, and the servers in Miami, New York, and London started getting much more traffic.
Read more about BGP and how we use and adjust it in AdGuard DNS.
This change tipped the scales and the RSA bomb has finally detonated, the servers weren't able to handle the increased load and started failing one by one. After 10 minutes we rolled back the routing changes to restore the traffic distribution. To our surprise this has not changed anything, the servers still could not cope with the load and the software was constantly killed & restarted.
We ran into a new problem. Now after a downtime all the DNS clients were trying to establish a new TLS connection and not just resume the existing session. This is exactly the case where RSA certs demonstrate the worst possible performance. On top of that, the increased load is created by millions of Android devices. We noticed that when Android's DoT reconnects to the server after a network change or after recovering from an error, it sends multiple "test" queries right away. These additional queries contribute to the server's load.
At first, we didn't realize where the root issue was. We wrongly thought it was a BGP misconfiguration since this was the thing that triggered the outage. In addition to that after several restarts and chaotic configuration changes we were able to recover London and New York. Reproducing these changes on Miami servers didn't help. This is when we calmed down and carefully inspected the software metrics and only then we identified the real cause of the disaster.
Incident timeline
- 18:24 UTC: Miami and New York servers go down due to the increased load.
- 18:45 UTC: BGP configuration has been rolled back but that doesn't help.
- 19:00 UTC: London servers also go down.
- 19:00—20:20 UTC: Chaotic configuration changes. London servers are going down without any obvious reason makes us think that the issue is BGP and maybe the routing is not restored.
- 20:20 UTC: London servers are recovered and operational again. At this point we don't understand what exactly has helped, but we try to reproduce the same configuration changes in other locations.
- 21:00 UTC: New York servers are recovered and operational. We finally realize that the root cause for the issue is the new RSA certs. We start changing the certs back everywhere.
- 21:30 UTC: While ECDSA certs are being prepared, we bring back Miami without DNS-over-TLS for the time being.
- 22:10 UTC: Miami is fully operational again.
Follow-up steps
In order to prevent this from happening again, we're taking both technical and organizational steps.
- We will be automatically checking the types of certificates and send an alert if the type is not ECDSA.
- Improve the deployments procedure. We could've noticed this issue earlier if we had analyzed the servers CPU graphs immediately after deploying the new certs. This should be done after any deployment even if the changes seem to be minuscule.
- Improve the internal incident response documentation. We are not happy with how the troubleshooting was conducted and it was possible to recover much, much faster.








