Partial AdGuard DNS Outage on 23 September 2024
Yesterday, at approximately 13:30 UTC, AdGuard DNS experienced a major outage that affected servers in several locations: primarily Frankfurt and Amsterdam, and London to a lesser extent. During this outage, Internet service was disrupted for some AdGuard DNS users. Our estimate is that around 25% of all users, or roughly 25 million people, were impacted.
We apologize for this incident and would like to explain what happened and what are the steps we are taking to prevent similar outages in the future.
What happened
First, let’s explain what exactly happened. To our great disappointment, while the incident was triggered by external factors, we should have been prepared for it, and in fact, we had been preparing for such situations. Nevertheless, you’re reading a post-mortem rather than a success story.
Before discussing the timeline, let’s briefly touch on how the AdGuard DNS infrastructure is set up. We’ve previously explained in detail how we use Anycast to handle massive amounts of queries from millions of users.
In short:
- AdGuard DNS servers are currently deployed in 15 locations worldwide.
- They handle more than 3 million queries per second (peaking close to 4 million), the majority of which use encrypted protocols (DoT/DoH/DoQ).
- The load across these locations is uneven. With Anycast, it's impossible to distribute the load evenly, and managing that distribution is extremely challenging.
The cause of the outage was quite simple: Internet traffic was rerouted, and a large portion of users from Asia were redirected from Asian locations to Frankfurt, which couldn’t handle the additional load.
What does "couldn’t handle the load" mean in our case? To prevent our software from crashing due to traffic spikes, AdGuard DNS limits the number of connections a server can handle simultaneously. For example, all servers in Frankfurt can handle no more than 3.3 million concurrent connections. This means that users who managed to establish a connection could use DNS normally, while others had to wait for "room to free up." This approach exists for a reason: the alternative — trying to handle all connections — would cause the system to crash due to a lack of memory under heavy load.
What makes this particularly frustrating is that Frankfurt, along with Singapore, was designed to handle increased loads. These two locations together should have been able to manage the entire AdGuard DNS traffic. Unfortunately, we didn’t manage to "fill" the location with enough servers in time. The servers were ordered long ago, but due to space constrains in the data center, we had to wait longer than usual.
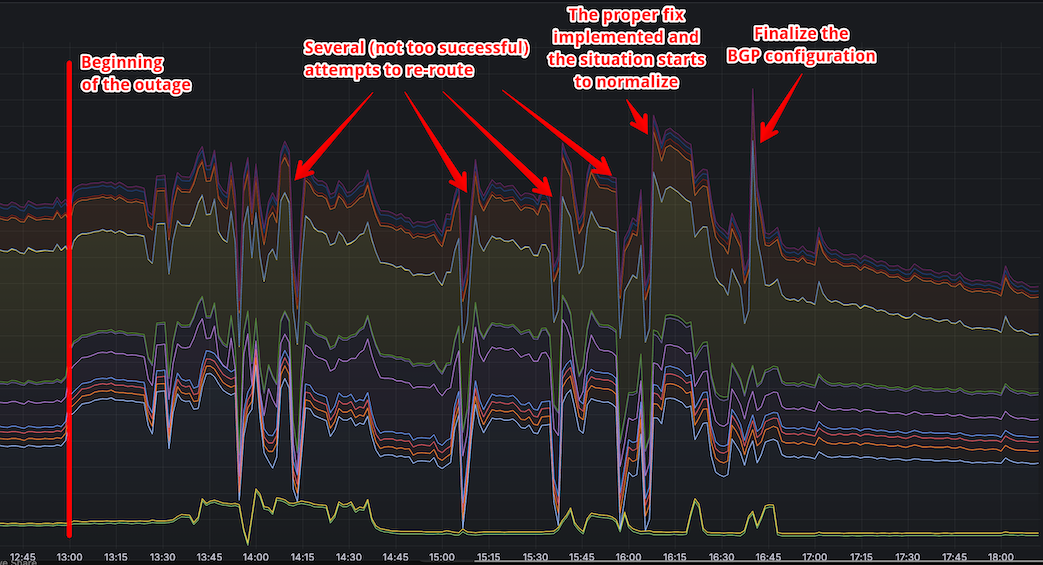
Now, why did it take so long to resolve the problem? The challenge is that it’s nearly impossible to predict how BGP configuration changes will affect traffic distribution. We had to rely on trial and error to find the correct configuration, and only after a couple of failed attempts did we get it right.
Incident timeline
- 13:00 UTC: Traffic from Asia is rerouted to Frankfurt.
- 13:00–13:30 UTC: Trying to figure out if the problem can be fixed without changing the BGP configuration.
- 13:30 UTC: First attempt to reroute traffic fails. Moreover, another large portion of traffic from Asia is now redirected to Amsterdam. The cause of this and the impact of changes in Frankfurt’s configuration remain unclear. London is also slightly affected.
- 13:30–14:00 UTC: BGP configuration is adjusted, normal operation is restored in London.
- 14:00–14:30 UTC: BGP configuration is adjusted, normal operation is restored in Amsterdam.
- 14:30–15:30 UTC: The BGP configuration is fine-tuned to route most of the traffic to Asia.
- 15:30–15:50 UTC: Monitoring the changes to make sure everything is working correctly.
Follow-up steps
Since BGP routing is difficult to manage reliably, our standard policy is to ensure that servers in each location can handle 3X the peak load (i. e., the load at the busiest time of the day). We try to adhere to this policy and purchase additional servers accordingly, but it’s clear that we haven’t been doing this well enough so far.
In the near future, we will increase capacity in key locations: Frankfurt and Amsterdam. While we await the delivery of the ordered servers, we will deploy additional resources and servers with configurations that differ from our usual setup.
Going forward, we will strictly adhere to our original policy regarding surplus capacity and find temporary solutions in case of delivery delays.








