2022年11月30日のAdGuard DNS部分的ダウンについて
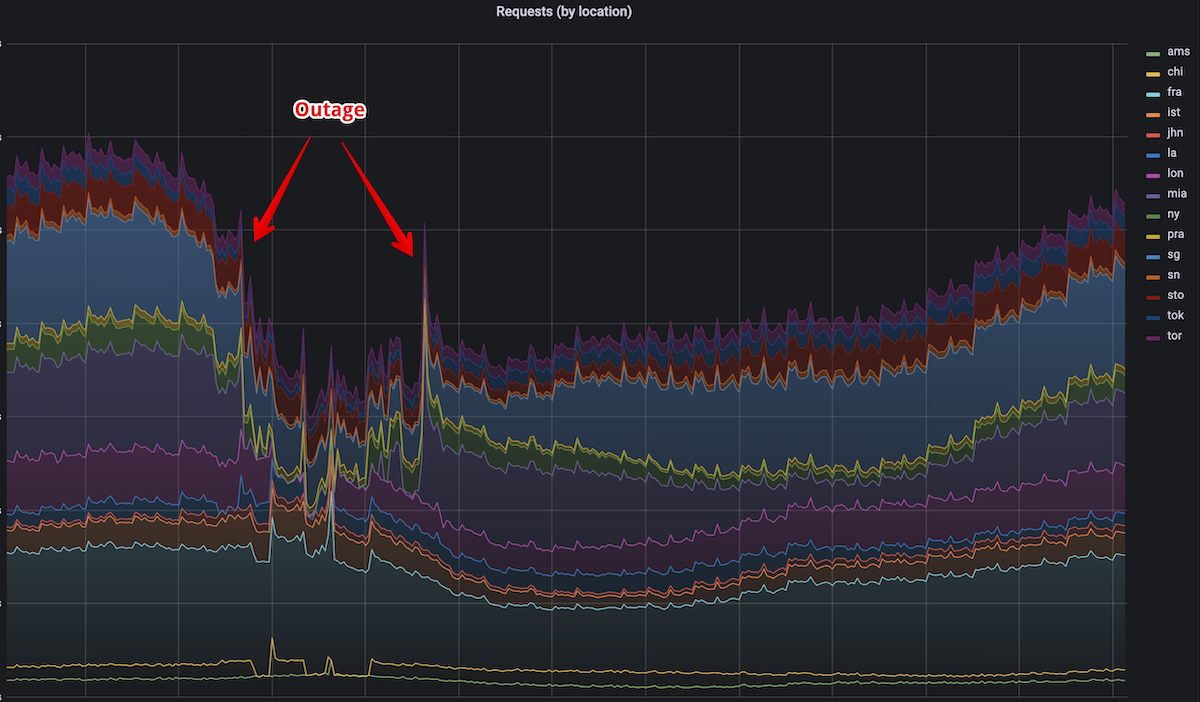
2022年11月30日03:24(東京)に、AdGuard DNSに深刻な障害が発生し、マイアミ、ニューヨーク、ロンドンの3ヶ所のサーバーが影響を受けました。
障害発生中、これら3つの拠点に接続されているすべてのお客様のインターネットが事実上遮断されました。
これは、AdGuard DNSの全顧客の約20%、すなわち1000万人以上の方がインターネットに問題を抱えたことになります。
影響を受けた方に、このような事態になったことを心からお詫び申し上げます。
今後このような問題が発生しないよう対策を講じる所存です。
何が起きたのか
小さなミスがいくつも重なり、問題発生に至りました。
これらのミスは、それぞれ単独なら致命的ではなく、障害を引き起こすものではありませんでした。
しかし、残念なことに、これらのミスが重なったことこそが、より大きなトラブルの原因となりました。
最初のミスは、11月28日にAdGuard DNSのTLS証明書を更新したときに起こりました。
新しい証明書はRSAで、いつも使っているECDSAではありませんでした。
この違いは、経験豊富な開発者にとっても明白ではないかもしれませんが、私たちにとっては非常に重要なものです。
AdGuard DNSはGoで書かれているため、多くの利点に加え、いくつかの制限も課されます。
RSAとの最初のTLSハンドシェイクは、Goのcrypto/tlsだと非常に遅く、この遅さは近いうちに修正されそうにないです。
このパフォーマンスの問題は主に最初のハンドシェイクに影響し、セッションの再開には影響しないので、証明書を変更した直後のCPU負荷の増加はそれほど大きくありませんでした。
しかし、その後の展開から見れば、これは“爆弾”が仕掛けられたようなもので、爆発する環境が整うのは時間の問題でした。
暗号化されていないプレーンDNSは、AdGuardのDNSトラフィックの約10%に過ぎません。トラフィックのほとんどはそれぞれの暗号化プロトコルであり、パフォーマンスの視点から暗号化で最も重いのはハンドシェイクです。
その1日後、私たちはBGP設定の変更を行いました。
これは、いくつかの小さなISPのトラフィック分散を改善するためのものでした。
この新しい設定で結構悪影響が出て、マイアミ、ニューヨーク、ロンドンのサーバーが受け取るトラフィック量がかなり増加しました。
BGPとAdGuard DNSでのその使用方法と調整方法については、こちらでもっと読むことができます。
この変更により、RSA“爆弾”がついに爆発しました。
サーバーは増加した負荷に対応できず、次々と故障し始めました。
10分後、私たちはルーティングの変更をロールバックして、トラフィックの分散を復元しました。
驚いたことに、これで何も変わりませんでした。
サーバーは依然として負荷に対処できず、ソフトウェアは常に停止し再起動し続ける状況でした。
そこでまた新たな問題が発生しました。
ダウンタイムの後、すべてのDNSクライアントが、既存のセッションを再開するのではなく、新しいTLS接続を確立しようとするようになったのです。
これはまさに、RSA証明書が最悪のパフォーマンスを発揮するケースです。
その上、何百万台ものAndroidデバイスによって負荷の増大が発生します。
AndroidのDoTは、ネットワークの変更後やエラーから回復した後にサーバーに再接続すると、すぐに複数の「テスト」クエリを送信することに気づきました。
これらのクエリーは、サーバーの負荷の一因となります。
当初、私たちは問題の根本がどこにあるのか分かりませんでした。
障害の引き金になったのはBGPの設定ミスだったので、BGPの設定ミスだと勘違いしていました。
さらに、何度も再起動し、無秩序な設定変更を行った結果、ロンドンとニューヨークを復旧させることができました。
しかしマイアミサーバーでこの変更を適用しても、改善は見られませんでした。
この時、私たちは落ち着いて、ソフトウェアの指標を慎重に調査し、初めて障害の本当の原因を特定しました。
本インシデントのタイムライン
- 03:24(東京) マイアミとニューヨークのサーバーが負荷の増加によりダウン。
- 03:45(東京) BGPの設定をロールバックしたが、効果なし。
- 04:00(東京) ロンドンのサーバーもダウン。
- 04:00-05:20(東京) カオス的な設定変更。ロンドンサーバーが明確な理由なくダウンしていることから、問題はBGPであり、ルーティングが復元されていない可能性があると予想。
- 05:20(東京) ロンドンサーバーは回復し、再び動作可能に。この時点で、何が改善に導いたのかは正確には分かっていないが、同じ設定変更を他のサーバーでも再現してみることに。
- 06:00(東京) ニューヨークのサーバーが復旧し、運用を開始。問題の根本原因が新しいRSA証明書であることにようやく気付きました。あらゆる場所で証明書の変更を再開。
- 06:30(東京) ECDSA証明書を準備している間、DNS-over-TLSなしでマイアミを復活。
- 07:10(東京) マイアミサーバーも再び完全に復旧。
フォローアップ手順と再発防止策
このような事態を二度と起こさないために、技術的および組織的な措置を講じています。
- 証明書の種類を自動的にチェックし、種類がECDSAでない場合はアラートを送信するようにします。
- デプロイプロセスを改善します。今回、新しい証明書を導入した直後にサーバーのCPUグラフを解析していれば、もっと早くこの問題に気づくことができたはずです。これは、たとえ変化が小さいように見えても、すべてのデプロイの後に行われるべきです。
- 内部インシデント対応ドキュメンテーションを改善。今回、トラブルシューティングの実施方法には満足していませんし、もっともっと早く復旧させることができるはずでした。








